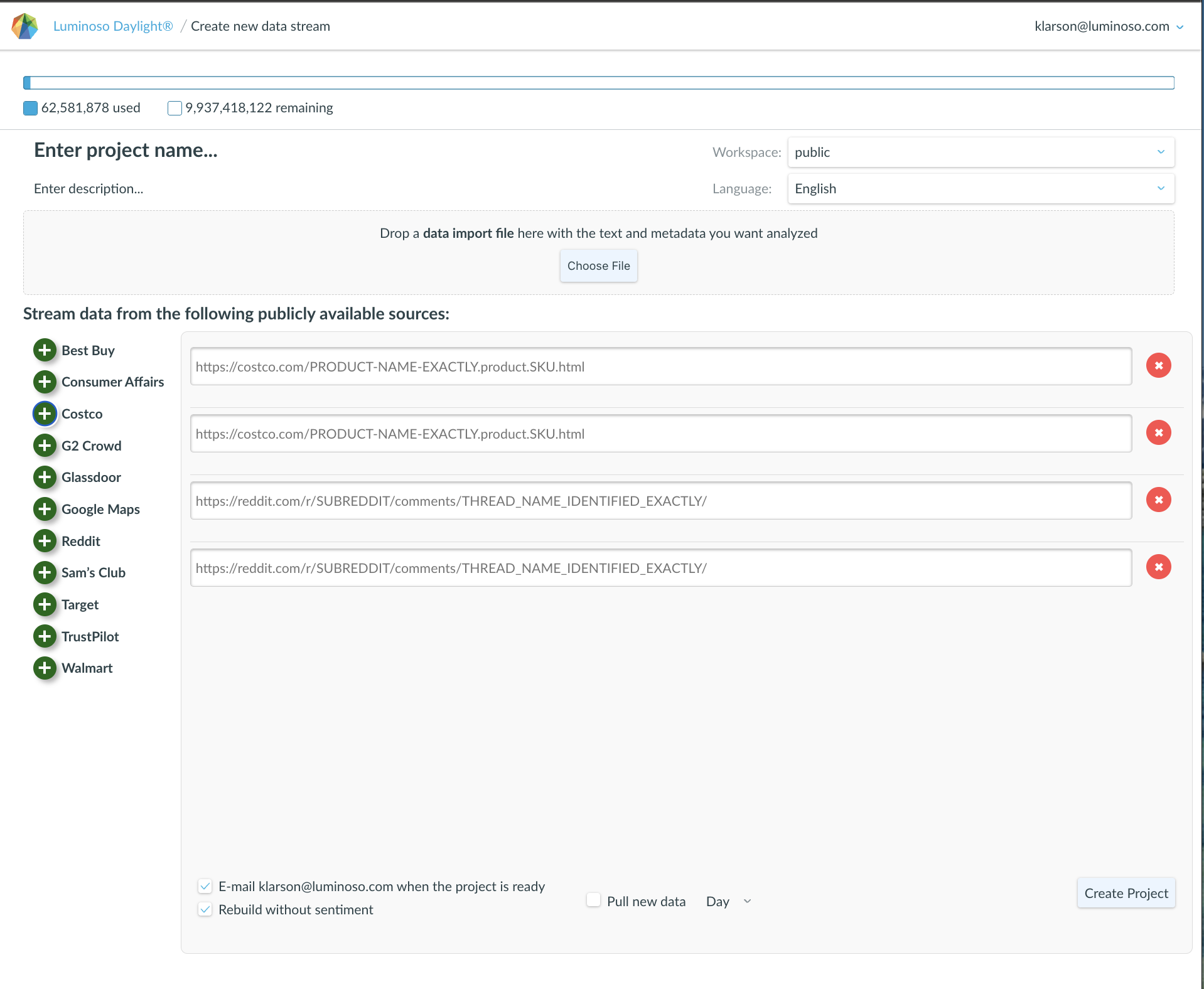
Now that you have an account on Daylight and access to a Workspace, the next step is to upload some text data to analyze. You can refer to the Using different data sources with Daylight page for some pointers on different types of text data to consider. You will also want to include some metadata to provide context for the text data, such as demographic information, dates, scores, etc. Metadata can be used to filter the data to analyze a subset of the data set, and numerical data can be used in Drivers analysis, which you will learn about later in this document.
VOCABULARY
CSV file
Stands for comma-separated value. It is a plain-text file format that is used to organize data. CSV files exclude styling information that is included in an Excel XLS or XLSX file formats. You can export a CSV file from most spreadsheet editors.
Metadata
A structured data that creates context for text responses. Metadata may include demographics, dates, scores, or product details.
Document
A row of your source data, including the conversational text and any associated metadata.
Verbatim
The conversational text component of the sample you have collected.
| Type | Description | Examples |
|---|---|---|
| Text (Required) | The natural language verbatims for Daylight to analyzeThere must be one and only one Text column per fileEach piece of Text may not exceed 500,000 characters in length | Column header:text or text_[FieldName]Values:I loved the free coffee and the room was very clean, but it smelled strongly of cigarette smoke.I booked this room last-minute when my travel plans changed. The price was ok considering it was last-minute but it was way out of the way.We come to this hotel every year, and we appreciate the consistently top-notch experience! |
| String | Words that help categorize the documentsCan only filter fields in Daylight with up to 10,000 valuesInclude as many string columns as needed | Column header:string or string_[MemberLevel]Values:StandardGoldPlatinum |
| Number | Numeric dataCan optionally use in the Driver featureInclude as many number columns as needed | Column header:number_[RoomNumber]Values:184157 |
| Score | Numeric dataCan optionally use in the Driver featureInclude as many number columns as needed | Column header:score_[NPS]Values:74.510 |
| Date | Date or timesAccepts ISO 8601 strings, Unix timestamps, or US-style formatsDaylight assumes that all dates are in a UTC timezone unless you include an ISO 8601 date with a specific timezoneHelps you filter your project, especially if you upload data more than onceInclude as many date columns as needed | Column header:date or date_[FieldName]ISO 8601 formatted dates:2018-04-1004/10/2018 13:45:152018-04-10T13:45US-style dates04/10/201804/10/2018 13:45:154/10/18 1:45 PM |
Sometimes, a metadata field can have multiple values within a single document. For example, a survey may ask the respondent “which of these products have you tried?”. In such a case, the respondent may select more than one product. There are two ways that you can format the data in such cases:
- Have one column for this metadata field and enter all of the values separated with the
|(pipe) character. In the example above, the column header can beProducts Usedand the value in a given cell could beProductA | ProductB | ProductC. - Have multiple columns with the same column header name with a single value in each cell. In the example above, you would have as many columns as you need with the header name
Products Usedand populate each cell with a single Product. Some of the cells can be left blank.
Supported languages and multilingual datasets
Daylight is capable of performing analysis natively in 15 languages. For best results with a multilingual dataset, split your data into one language per upload file. Each language will be uploaded and analyzed as its own Project.
Save as a CSV file
Daylight is capable of performing analysis natively in 15 languages. For best results with a multilingual dataset, split your data into one language per upload file. Each language will be uploaded and analyzed as its own Project.